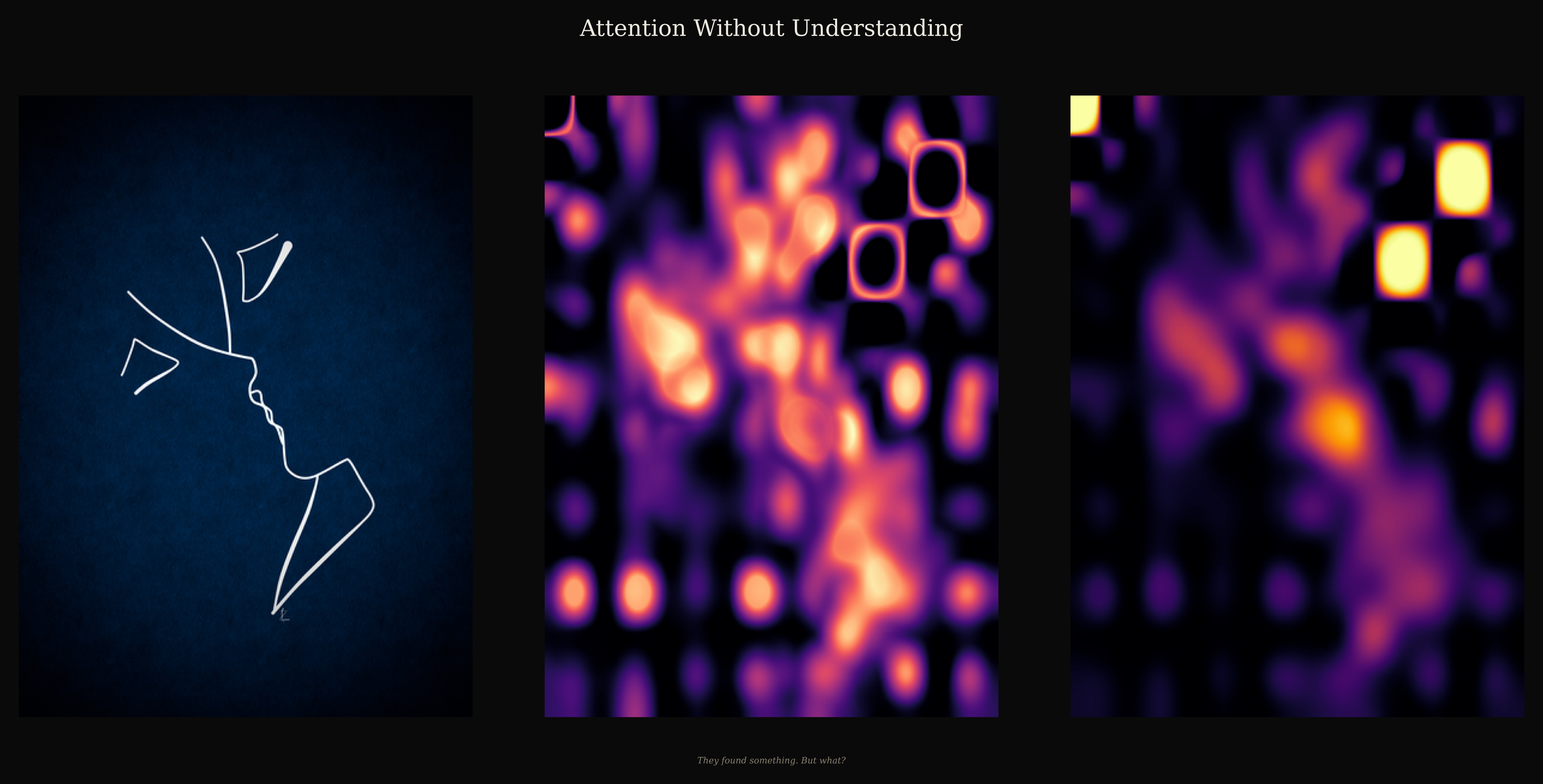
A line drawing. No instruction. DINOv2 attended to it through twelve independent heads, each weighting the image differently, none aware of the others.
Like the inhabitants of Plato’s Cave, the model perceives only the shadows of geometry, forever separated from the “Form” by a veil of its own making.
It found something. But what?
Left: The Form
Centre: The Conflict
Right: The Gaze
Technical note: The centre panel visualises the standard deviation across twelve individual self-attention heads; the right panel visualises the mean attention across the same heads. These maps are derived from the final transformer block of DINOv2 ViT-B/14 via the [CLS] token, and projected into image space using bicubic interpolation and Gaussian smoothing.
Artist Statement
This work uses the self-attention mechanism of DINOv2 to explore a form of digital Platonic realism. While the model can map the “shadows” of the image, edges and spatial patterns, it lacks noesis, the highest form of reason, the capacity to access the semiotic structure through which humans read meaning in even a single line.
By stripping away labels and technical clutter, the triptych focuses on the ontological gap between human intention and algorithmic perception. The work invites the viewer to witness a machine trapped within its own cave, attending to shadows it can never truly understand.
Technical Deep Dive: The Twelve Gazes
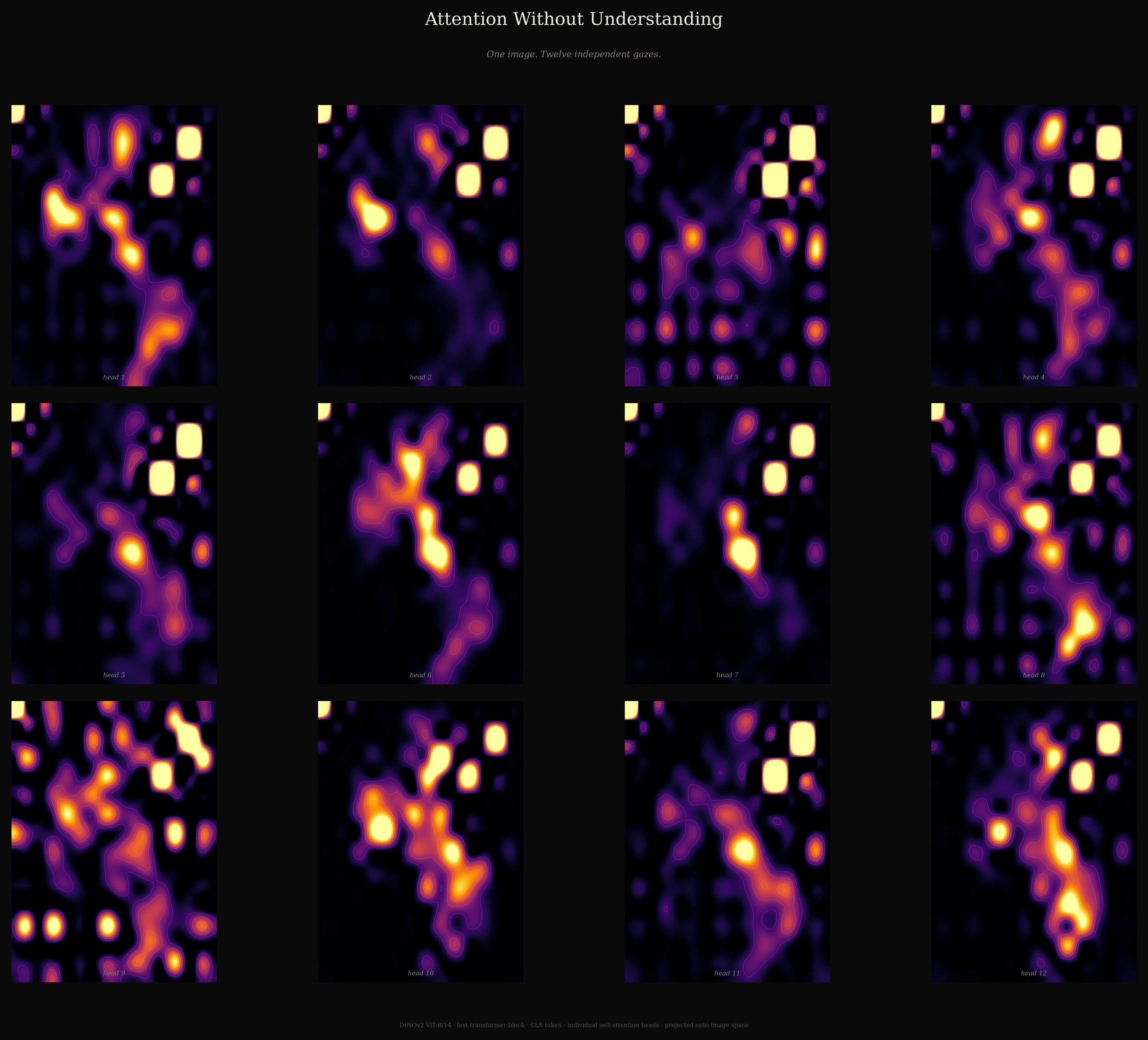
Output of twelve individual self-attention heads from the last transformer block of DINOv2.
One image. Twelve independent gazes.
This visualisation probes the internal logic of the DINOv2 (ViT-B/14) architecture. Unlike supervised models that are explicitly trained to recognise labelled objects, DINOv2 is self-supervised: it learns visual structure through self-distillation.
The grid above displays the individual attention heads from the final transformer block, extracted via the [CLS] token. The result reveals a fragmented machine perception. Some heads focus on local curvature, such as the lips and chin. Other heads attend to global spatial relationships or negative space. The variance between them exposes a model that can identify patterns while lacking semantic grounding.
The image below shows “The Alignment of Gaze”: an overlay of Head 10 on the original drawing, demonstrating the mathematical precision with which transformer attention isolates salient edges without semantic understanding.

The Alignment of Gaze.